理论分析:基于实测的生命科学计算性能规律
完整呈现 8 种 CPU 节点与 6 种 GPU 节点、15 款代表性软件的评测数据,揭示集群核心组成对生命科学计算性能的影响规律。
测试环境与数据集
硬件环境
- 8 种 CPU 节点(CPU1 ~ CPU8):涵盖不同代际、核心数与架构
- 6 种 GPU 节点(GPU1 ~ GPU6):涵盖 NVIDIA 不同产品线
- 网络环境:1GbE 与 InfiniBand 对比测试
测试数据集
- 每款软件配备 三种规模数据集(Case A/B/C),数据量级相差一个数量级
- 所有数据集均来自实际科研项目(千人基因组、ENCODE 等)
- 确保评测结果反映真实科研场景下的性能表现
软件资源需求特征分析
基于归一化互信息(NMI)方法,对不同软件在运行过程中的 CPU 使用率、内存用量、I/O 读写带宽、功耗等多维指标进行资源需求特征分析。
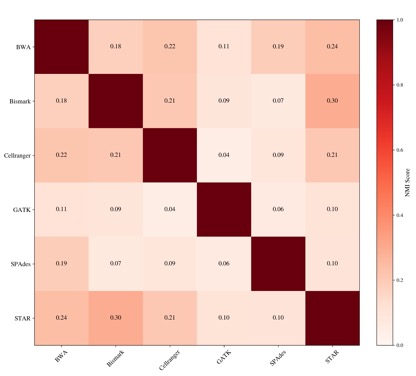
图 3-1:CPU 应用软件资源需求特征相似性热图
基于 NMI 的相似性矩阵,颜色越深表示资源需求模式越相似
核心发现
- CPU 应用软件资源需求特征差异明显,NMI 值普遍较低
- 不同软件对 CPU、内存、I/O 的依赖模式各不相同,验证了“一刀切”评测的局限性
- GPU 应用中,分子动力学模拟类软件(AMBER、GROMACS、SPONGE)特征相对接近,与 DSDP、AlphaFold3 差异较大
图 3-16:资源需求峰值聚类
各软件在不同规模数据集和配置下的资源需求峰值聚类分析
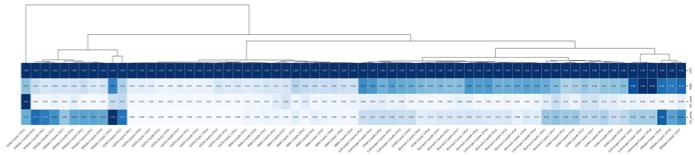
相同软件在不同配置和数据规模下资源需求特征存在差异,说明算法会随数据量级改变资源利用模式。 但资源需求峰值聚类结果显示,相同软件总能聚类在一起,表明其内在资源需求模式相对稳定。
集群核心组成对计算性能的影响
CPU 对计算性能的影响
表 3-1 / 表 3-2 / 图 3-7 / 图 3-8
通过 8 种不同 CPU 节点运行 6 款 CPU 应用软件(BWA、Bismark、Cellranger、GATK、SPAdes、STAR), 分析 CPU 对实际应用性能的影响。
关键发现
图 3-8:Linpack vs BioProfile 性能得分
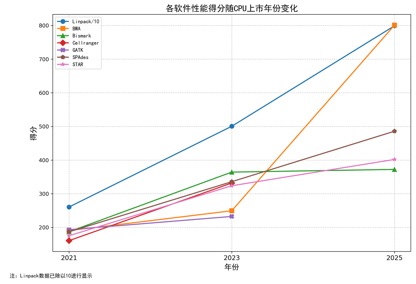
GPU 对计算性能的影响
表 3-3 / 表 3-4
- GPU 型号对计算性能影响显著,高浮点性能的 GPU 在分子动力学模拟和 AI 推理中优势明显
- 部分软件(如 AMBER)在 8 卡并行时,性能提升幅度与单卡性能并非线性相关,需关注节点内 GPU 间通信带宽
- AI 应用(AlphaFold3)对 GPU 显存和算力有特殊要求,选型时需综合考虑
CPU 对 GPU 应用计算性能的影响
表 3-5
相同 GPU 型号搭配不同 CPU(2×32 核 vs 2×64 核)的测试表明:CPU 核心数与主频对 GPU 应用性能有显著影响。 更高主频 CPU 上各软件普遍表现更优,说明 CPU 仍是 GPU 计算中的重要影响因素,不应被忽视。
软件基础环境对计算性能的影响
表 3-6
相同硬件使用不同编译器/数学库(通用 vs 定制)时,GATK 和 SPAdes 的性能对比表明: 定制编译器与优化数学库可带来最高达 185% 的性能提升(GATK CaseB)。 软件环境优化是提升集群效率的重要且低成本的手段。
I/O 带宽对计算性能的影响
表 3-7
I/O 密集型应用
Cellranger、STAR 等对存储带宽极为敏感,带宽提升可带来数十倍甚至上百倍的效率提升。
计算密集型应用
BWA 大数据集等对 I/O 带宽不敏感,性能提升主要体现在 CPU 算力上。
节点间通信对计算性能的影响
表 3-8
通信密集型应用
NAMD 等对网络带宽和延迟高度敏感,InfiniBand 相比 1GbE 可提升 100% 以上效率。
计算密集型应用
LAMMPS 大数据集等对网络不敏感,计算时间主要由计算负载决定。
单任务计算用时稳定性分析
在完全相同的软硬件环境下,使用全部 CPU 核心运行同一软件、同一数据集,重复 10 次,记录每次的计算用时。
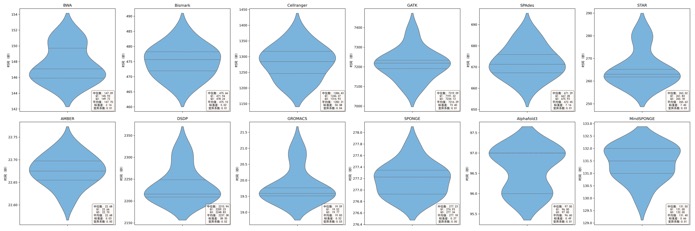
图 3-9:各软件计算用时分布(小提琴图)
重复 10 次运行的用时分布,反映系统噪声水平
CPU 应用
变异系数在 0.01 ~ 0.04 之间,受系统噪声影响略大
GPU 应用
变异系数均小于 0.03,评测结果可再现性更高
并行加速比特征
通过在不同线程数下运行同一软件和数据集,分析并行加速比特征。每种软件 3 个数据集,共 36 组加速比测试。
并行加速比特征相关性热图
图 3-53 ~ 3-58:各软件在不同测试环境下的并行加速比特征相似性
核心结论:除个别例外,每个软件在不同测试环境下使用不同规模数据集, 其并行加速比特征都非常相似。说明并行效率模式具有稳定性,可通过单次测试为大批量任务提供可靠指导。
大批量任务并行运行策略对计算效率的提升
通过枚举所有可行的并行组合(任务数 × 每个任务线程数),运行大批量独立任务,找到总用时最短的最佳并行策略。
图 3-59:BWA 不同并行模式计算用时
横轴为并行模式,纵轴为总用时,红点标注最佳模式
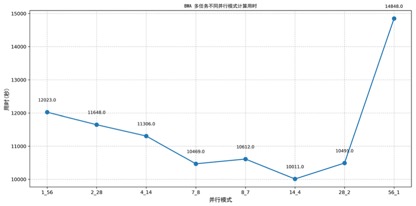
表 3-9:各软件最差与最佳并行策略对比
| 软件 | 数据集 | 最差策略 | 最佳策略 | 效率提升 |
|---|---|---|---|---|
| BWA | CaseA | 1×56 | 14×4 | 71% |
| BWA | CaseB | 1×56 | 7×8 | 115% |
| BWA | CaseC | 1×56 | 4×14 | 236% |
| Bismark | CaseA | 1×56 | 7×8 | 89% |
| Bismark | CaseB | 1×56 | 7×8 | 108% |
| Bismark | CaseC | 1×56 | 4×14 | 201% |
| Cellranger | CaseA | 1×56 | 14×4 | 63% |
| GATK | CaseA | 1×56 | 14×4 | 61% |
| SPAdes | CaseA | 1×56 | 1×56 | 0% |
| STAR | CaseA | 1×56 | 14×4 | 112% |
| STAR | CaseB | 1×56 | 14×4 | 544% |
核心发现:不同并行模式对计算效率影响显著,最佳策略相较最差策略效率提升最高可达 544%(STAR CaseB)。推荐并行模式可直接用于作业调度优化。
GPU 集群深度测评实测及分析
在 128 节点 GPU 集群上,对 DSDP、AMBER、GROMACS、SPONGE、AlphaFold3 进行集群整体性能评测。
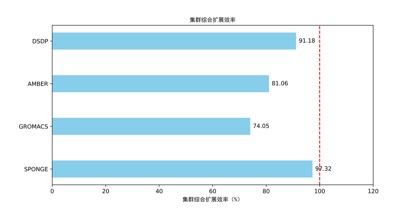
集群扩展效率(CPU 评估模块)
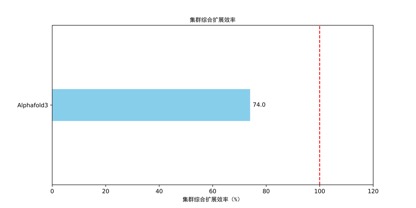
集群扩展效率(GPU 评估模块)
集群瓶颈发现
AMBER、GROMACS、AlphaFold3 的扩展效率约 74% ~ 81%,推测存在通信或存储瓶颈。
双层分析价值
单节点深度分析可定位节点级瓶颈,集群测试可暴露系统级瓶颈,二者结合指导集群优化。